

Automate document validation and fraud detection in the mortgage underwriting process using AWS AI services: Part 1
[ad_1]
In this three-part series, we present solutions that demonstrate how you can automate tampering and fraud detection at scale using AWS AI and machine learning (ML) services for mortgage underwriting use cases.
This solution follows a more significant global wave of increased mortgage fraud, which has only gotten worse as more people provide evidence of fraud to qualify for loans. Data shows high-risk mortgage fraud activity and suspected fraud is on the rise, noting a 52% increase in suspected fraudulent mortgage applications since 2013. (Source: equifax)

Part 1 of this series covers the most common challenges associated with manual lending processes. We provide concrete guidance on addressing this issue with AWS AI and ML services to detect tampering with documents, identify and categorize patterns of fraud scenarios, and integrate with business-defined rules while minimizing human expertise for fraud detection.
In Part 2, we demonstrated how to train and host a computer vision model for tamper detection and localization in Amazon SageMaker. In Part 3, we show how to automate fraud detection in mortgage documents with ML models and business-defined rules using Amazon Fraud Detector.
Challenges associated with the manual loan process
Organizations in the lending and mortgage industry receive thousands of applications, ranging from new mortgage applications to refinancing existing mortgages. These documents are increasingly vulnerable to document fraud as fraudsters try to exploit the system and qualify for mortgages in several illegal ways. To qualify for a mortgage, applicants must provide the lender with documents verifying their employment, assets and debts. Changing loan rules and interest rates can drastically change an applicant’s credit affordability. Fraudsters range from beginners who err to near-perfect masters when creating fake loan application documents. Fraudulent documents include but are not limited to altering or falsifying payslips, inflating income information, misrepresenting employment status, and falsifying employment papers and other important mortgage guarantee documents. These attempts at fraud can be challenging for mortgage lenders to catch.
Significant challenges associated with the manual loan process include but are not limited to:
- The need for borrowers to visit the branch
- Operating costs
- Data entry error
- Automation and turnaround times
Finally, the underwriting process, or creditworthiness analysis and loan decisions, requires additional time if done manually. Again, the manual consumer lending process has several advantages, such as approving loans that require human judgement. This solution will provide automation and risk mitigation in mortgage underwriting which will help reduce time and costs compared to manual processes.
Solution overview
Document validation is an important type of input for mortgage fraud decisions. Understanding the risk profile of mortgage support documents and driving insights from this data can significantly improve risk decisions and is at the heart of any underwriter’s fraud management strategy.
The following diagram represents each stage in the mortgage document fraud detection pipeline. We explore each of these stages and how they help with underwriting accuracy (beginning with capturing documents to classify and extract the required content), detecting tampered documents, and finally using ML models to detect potential fraud classified according to business-driven rules.
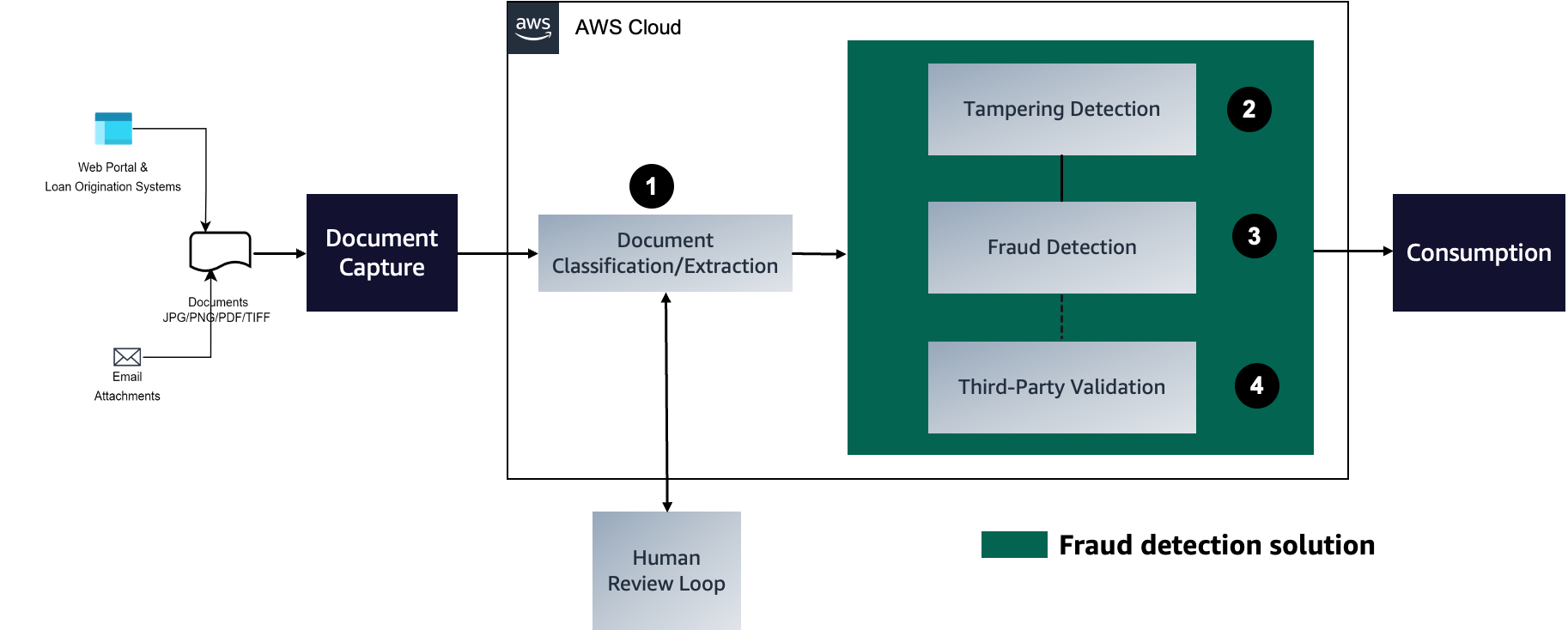
In the following sections, we discuss the process stages in detail.
Document classification
With intelligent document processing (IDP), we can process financial documents automatically using AWS AI services such as Amazon Texttract and Amazon Comprehend.
In addition, we can use the Amazon Texttract Analyze Lending API to process mortgage documents. Loan Analysis uses trained ML models to automatically extract, classify, and validate information in mortgage-related documents with high speed and accuracy while reducing human error. As depicted in the following figure, Loan Analysis accepts loan documents and then divides them into pages, classifying them according to document type. Document pages are then automatically routed to Amazon Textract’s text processing operations for accurate data extraction and analysis.
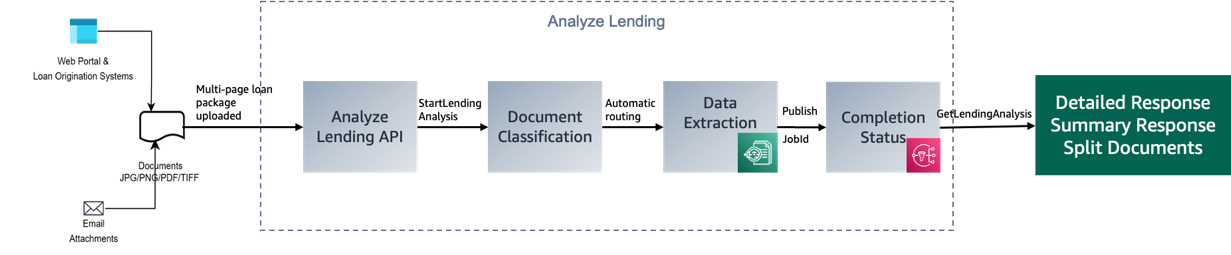
The Analyze Lending API offers the following benefits:
- Automated end-to-end mortgage package processing
- The ML model is trained in various types of documents in the mortgage application package
- Ability to scale on demand and reduce dependence on human reviewers
- Better decision making and significantly lower operating costs
Tamper detection
We use a computer vision model implemented in SageMaker for our end-to-end image detection and localization solution, which means it takes a test image as input and predicts possible pixel-level spoofing as output.
Most research studies focus on four image manipulation techniques: splicing, copy-move, removal, and enhancement. Both splicing and copy-move involve adding image content to a (fake) target image. However, the added content is obtained from a different image in splicing. In copy-move, it’s from the target image. Erasing, or repainting, removes the selected image area (for example, hiding an object) and fills in the space with the new estimated pixel value of the background. Finally, image enhancement is a huge collection of local manipulations, such as sharpening, brightness, and adjustments.
Depending on the characteristics of counterfeiting, different clues can be used as the basis for detection and localization. These clues include JPEG compression artifacts, edge inconsistencies, noise patterns, color consistency, visual similarity, EXIF consistency, and camera model. However, real-life fakes are more complex and often use a series of manipulations to hide the fakes. Most of the existing methods focus on image-level detection as to whether an image is spoofed or not, rather than localizing or highlighting spoofed areas of the document image to assist the underwriter in making an informed decision.
We cover the details of implementing training and hosting a computer vision model for tamper detection and localization in SageMaker in Part 2 of this series. The conceptual architecture of the CNN-based model is depicted in the following diagram. The model extracts feature traces of image manipulation for test images and identifies anomalous regions by assessing how different the local features are from their reference features. It detects spoofed pixels by identifying local anomalous features as masks predicted from test images.
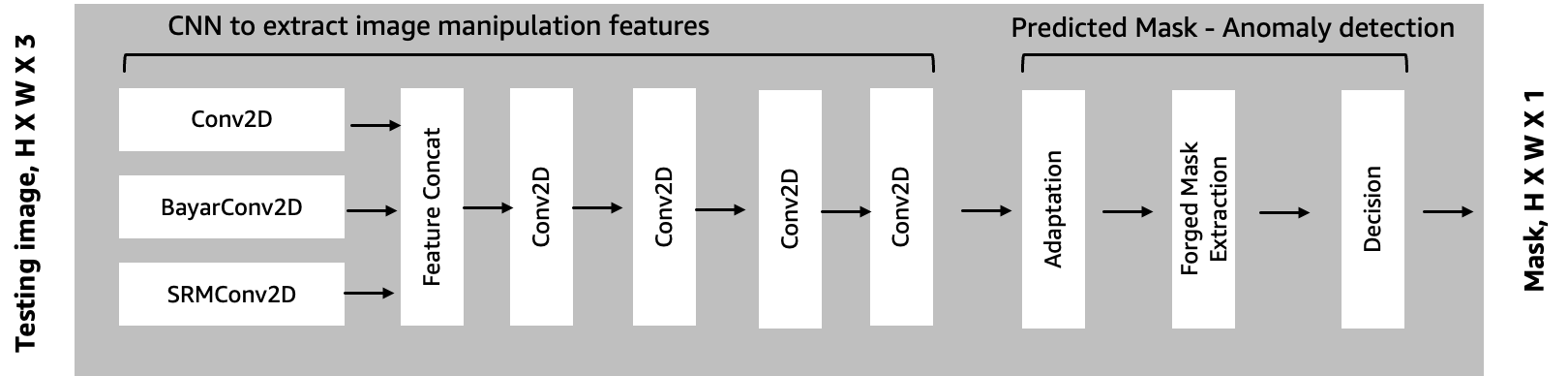
Fraud detection
We use Amazon Fraud Detector, a fully managed AI service, to automate the creation, evaluation, and detection of fraudulent activity. This is achieved by making fraud predictions based on data extracted from mortgage documents against an ML fraud model trained with historical (fraud) customer data. You can use those predictions to trigger business rules regarding underwriting decisions.
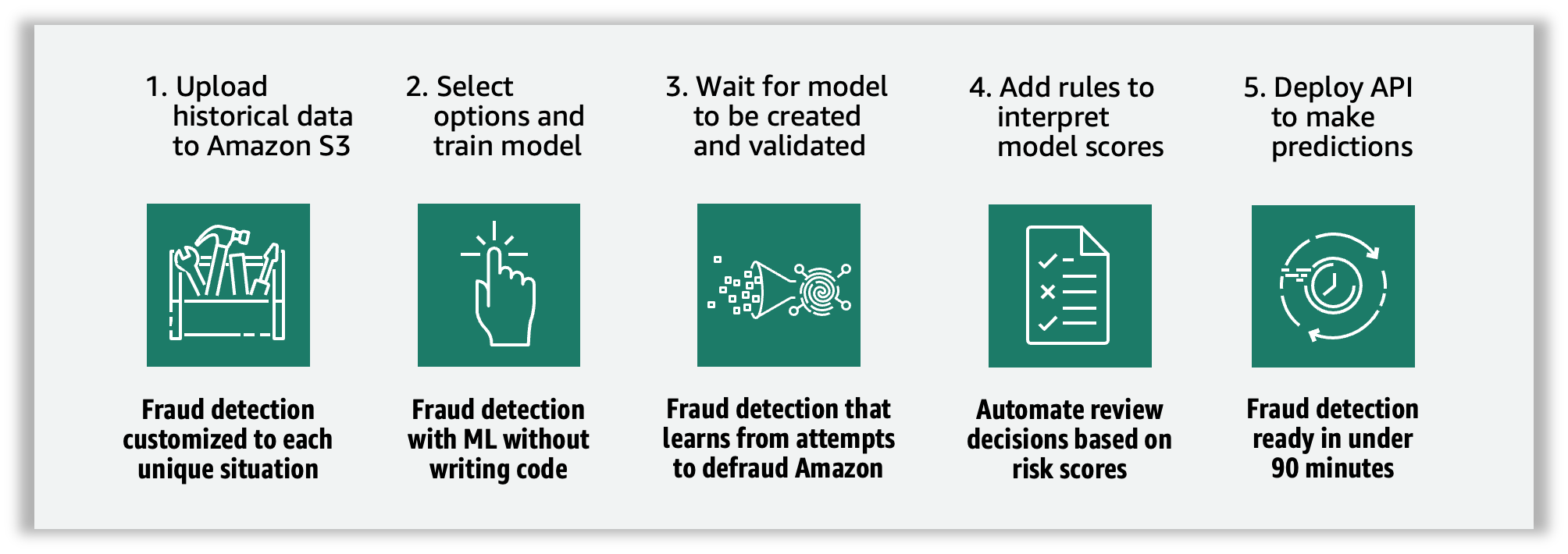
Defining fraud prediction logic involves the following components:
- Event type – Define event structure
- Model – Define algorithms and data requirements to predict fraud
- Variable – Represents data elements associated with fraud detection events
- Rule – Tell Amazon Fraud Detector how to interpret variable values during fraud prediction
- Results – Results generated from fraud predictions
- Detector version – Contains fraud prediction logic for fraud detection events
The following diagram illustrates the architecture of this component.
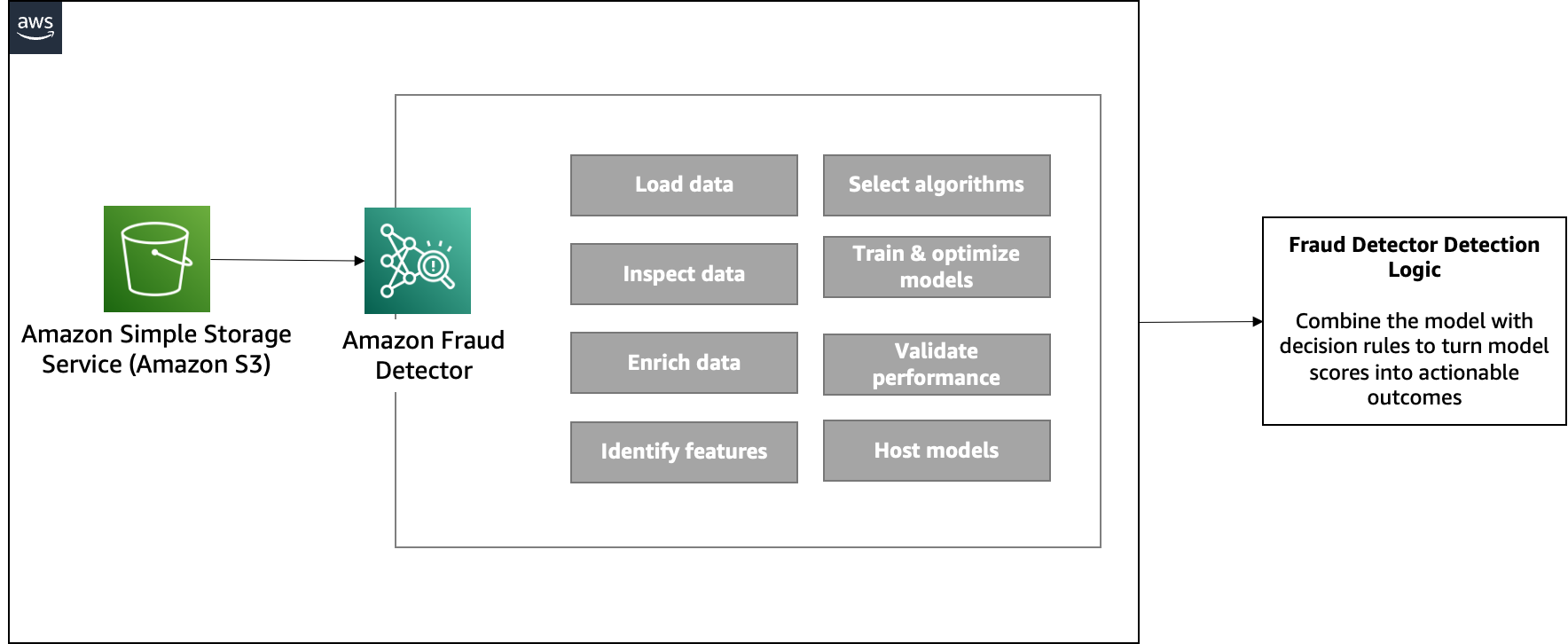
Once you’ve implemented your model, you can evaluate its performance scores and metrics based on predictive explanations. This helps identify top risk indicators and analyze fraud patterns across data.
Third party validation
We integrate solutions with third party providers (via API) to validate information extracted from documents, such as personal and employment information. This is especially useful for cross-validating details in addition to document tampering detection and fraud detection based on application historical patterns.
The following architectural diagram illustrates a batch-oriented fraud detection pipeline in processing mortgage applications using various AWS services.
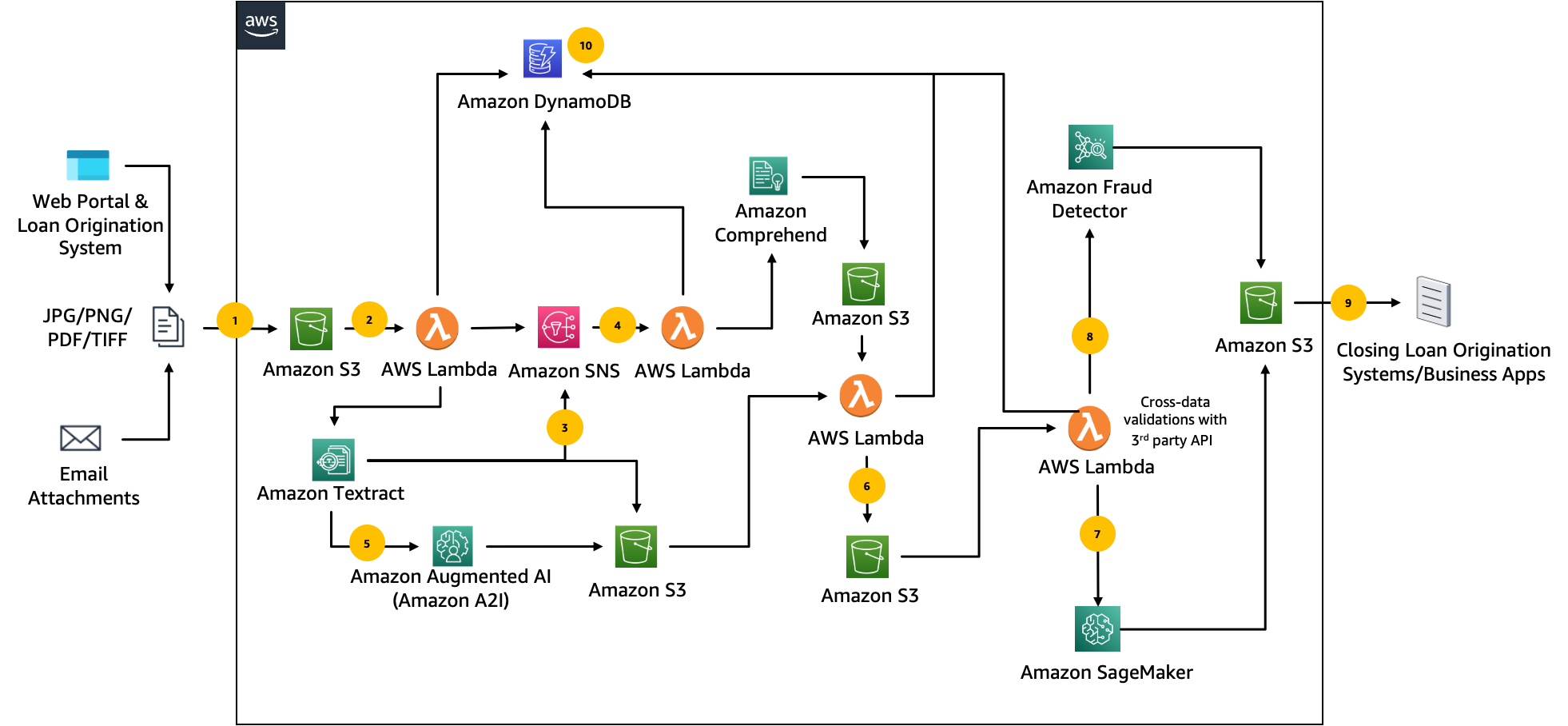
The workflow includes the following steps:
- Users upload scanned documents to Amazon Simple Storage Service (Amazon S3).
- The upload triggers an AWS Lambda (Invoke Document Analysis) function that calls the Amazon Texttract API for text extraction. Additionally, we can use the Amazon Texttract Analyze Lending API to automatically extract, classify, and validate information.
- Once text extraction is complete, notifications are sent via Amazon Simple Notification Service (Amazon SNS).
- The notification triggers a Lambda function (Get Document Analysis), which calls Amazon Comprehend for custom document classification.
- The analysis results of documents that have a low confidence score will be passed on to human reviewers using Amazon Augmented AI (Amazon A2I).
- The output from Amazon Texttract and Amazon Comprehend is combined using Lambda (Document Analysis & Classification) functions.
- The SageMaker inference endpoint is called for the fraud prediction mask from the input document.
- Amazon Fraud Detector is called for a fraud prediction score using data retrieved from mortgage documents.
- Results from Amazon Fraud Detector and SageMaker inference endpoints are aggregated into loan origination applications.
- The status of document processing jobs is tracked in Amazon DynamoDB.
Conclusion
This post walks through automated solutions for detecting document tampering and fraud in mortgage underwriting processes using Amazon Fraud Detector and other Amazon AI and ML services. This solution allows you to detect fraud attempts closer to the time they occur and assists underwriters with an effective decision-making process. Implementation flexibility allows you to define business-based rules to classify and capture fraud attempts tailored to specific business needs.
In Part 2 of this series, we provide implementation details for detecting document tampering using SageMaker. In Part 3, we demonstrated how to implement a solution in Amazon Fraud Detector.
About the Author
 Anup Ravindranath is a Senior Solutions Architect at Amazon Web Services (AWS) based in Toronto, Canada, working with Financial Services organizations. He helps customers transform their business and innovate in the cloud.
Anup Ravindranath is a Senior Solutions Architect at Amazon Web Services (AWS) based in Toronto, Canada, working with Financial Services organizations. He helps customers transform their business and innovate in the cloud.
 Vinnie Saini is a Senior Solutions Architect at Amazon Web Services (AWS) based in Toronto, Canada. He has helped Financial Services customers transform in the cloud, with AI and ML-based solutions that sit on top of a strong foundational pillar of Architectural Excellence.
Vinnie Saini is a Senior Solutions Architect at Amazon Web Services (AWS) based in Toronto, Canada. He has helped Financial Services customers transform in the cloud, with AI and ML-based solutions that sit on top of a strong foundational pillar of Architectural Excellence.
[ad_2]
Source link



